

Mengupas Tuntas Generative AI di Edge: Apa dan Bagaimana Cara Kerjanya ?
EDUCATION
Artikel asli oleh Jennie Wang, Seeed Studio AIoT Marketing and Partnership Diterjemahkan oleh : Digiware
8/7/20245 min read
Terobosan signifikan berikutnya dalam AI modern datang dengan munculnya GPT (Generative Pre-trained Transformer). Dengan memanfaatkan sejumlah besar data dari internet, teknologi inti GPT telah memungkinkan model AI menjadi lebih umum. Tanpa keterbatasan pendekatan AI konvensional seperti sangat bergantung pada aturan dan pola yang telah ditentukan sebelumnya, atau bahkan membiarkan mesin membuat prediksi berdasarkan hubungan antara data dan label yang dipelajarinya. Dalam gelombang Generatif, kita dapat membuat hasil yang fleksibel dan tak terbatas hanya dengan memberikan perintah secara singkat atau lisan kepada mesin, membuat hidup lebih nyaman dan cerdas. Sekarang, mari kita mendalami cara memahami AI generatif di edge, dan apa yang bisa kita lakukan dengan Generative AI!
Generative AI dirancang untuk mempelajari pola dalam data tak terstruktur berdasarkan jaringan saraf deep learning. Menggunakan kombinasi metode unsupervised dan semi-supervised dalam pelatihan awalnya, ia juga mengintegrasikan teknik supervised selama penyesuaian akhir. Ini memungkinkan model untuk secara mandiri membuat konten baru dan asli dengan efisiensi dan presisi yang lebih baik di berbagai domain—baik teks, gambar, audio, atau data sintetis.
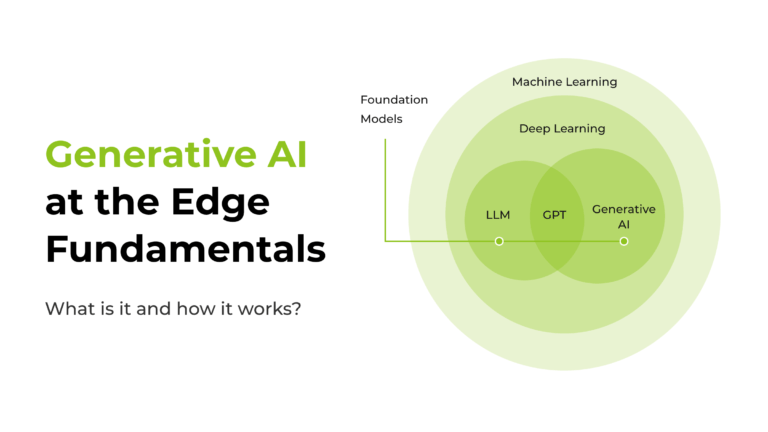
Apa itu Generative AI ?
Struktur di Balik Generative AI
Konsep AI Generatif, yang merujuk pada model yang telah dilatih sebelumnya dan berfungsi sebagai titik awal untuk berbagai tugas turunan, memanfaatkan Transformer sebagai arsitektur dasarnya. Model dasar ini dibangun dan dilatih dengan sejumlah besar data. Setelah dilatih, model tersebut dapat disesuaikan untuk tugas tertentu atau digunakan sebagaimana adanya untuk berbagai aplikasi kreatif, seperti generasi bahasa, pelengkapan teks, atau bahkan sintesis gambar.
Transformer
Kerangka Transformer adalah arsitektur terobosan dalam pemrosesan bahasa alami, yang ditandai dengan struktur encoder-decoder dan mekanisme self-attention yang memproses seluruh input secara bersamaan, bukan memproses vektor satu per satu secara berurutan.
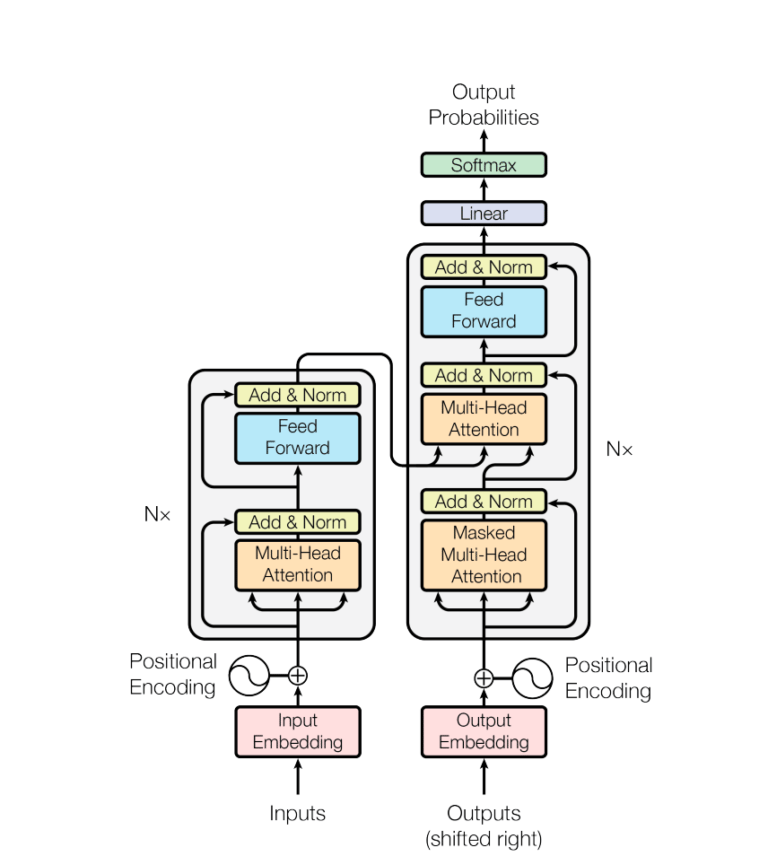
Dalam encoder, urutan input menjalani multi-head self-attention, memungkinkan model untuk fokus pada berbagai bagian urutan secara bersamaan. Decoder, yang bertanggung jawab untuk menghasilkan urutan output, menggunakan mekanisme serupa sambil mengintegrasikan komponen tambahan seperti positional encoding untuk mempertahankan urutan kata. Jaringan saraf feedforward di dalam setiap lapisan memproses informasi yang diperoleh dari mekanisme perhatian, memungkinkan model untuk menangkap hubungan kompleks dalam data. Selain itu, layer normalization dan residual connections berkontribusi pada pelatihan yang stabil dan efisien, memungkinkan model untuk secara efektif mempelajari pola-pola rumit dalam data berurutan.
Arsitektur model transformer. Gambar dari makalah “Attention Is All You Need”
Foundation Model
Memahami kerangka model dasar melibatkan pengakuan perannya sebagai model yang telah dilatih sebelumnya dan berfungsi sebagai titik awal untuk berbagai tugas turunan.
Ambil contoh model bahasa seperti GPT, model dasar dilatih pada dataset yang luas dan beragam menggunakan pembelajaran tanpa pengawasan. Selama fase pelatihan awal ini, model mempelajari nuansa bahasa, menangkap hubungan kontekstual dan pola-pola. Model dasar yang dihasilkan kemudian disesuaikan untuk tugas atau aplikasi tertentu, mengadaptasi pengetahuan yang telah dipelajari sebelumnya untuk mengatasi tantangan yang lebih khusus.
Pendekatan pelatihan awal diikuti dengan penyesuaian ini memberdayakan model dasar untuk unggul dalam berbagai tugas terkait bahasa, mulai dari pelengkapan teks hingga analisis sentimen. Mari kita lihat beberapa model dasar klasik yang dapat diterapkan di Edge:
LLM, atau “Large Language Model,” adalah model kecerdasan buatan yang kuat dalam konteks pemrosesan bahasa alami dan pembelajaran mesin. Dilatih secara ekstensif pada data tekstual yang beragam, model ini unggul dalam memahami dan menghasilkan bahasa yang mirip dengan manusia. Model yang serbaguna ini dapat disesuaikan dengan sangat baik untuk memenuhi tugas atau domain bahasa tertentu. Salah satu aplikasi signifikan dari LLM adalah Llamaspeak, sebuah aplikasi obrolan interaktif inovatif yang memanfaatkan teknologi NVIDIA Riva ASR/TTS secara langsung, memungkinkan pengguna untuk terlibat dalam percakapan vokal dengan LLM yang berjalan secara lokal, meningkatkan sifat interaktif dan dinamis dari komunikasi. Cek panduan tentang cara membangun chatbot lokal dengan Riva dan Llama2 pada reComputer.


CLIP, singkatan dari Contrastive Language-Image Pretraining, adalah model visi komputer yang dikembangkan oleh OpenAI. Model ini unggul dalam memahami hubungan antara gambar dan deskripsi teks yang sesuai, dibangun berdasarkan penelitian mendalam tentang transfer zero-shot, pengawasan bahasa alami, dan pembelajaran multimodal. Dengan CLIP, Anda hanya perlu mendefinisikan kemungkinan prompt atau deskripsi yang relevan dengan objek dalam gambar, kemudian CLIP akan membantu Anda memprediksi kelas yang paling mungkin untuk gambar atau video yang diberikan berdasarkan pelatihan yang luas. Salah satu aplikasi ilustratif dari CLIP adalah mengotomatiskan proses pelabelan menggunakan Vision Transformers (OWL-ViT) bersama CLIP. Ini memungkinkan deteksi dan klasifikasi objek zero-shot, tidak hanya menyederhanakan alur kerja pelabelan, tetapi juga memperluas kemampuan model untuk mengklasifikasikan objek yang belum pernah ditemui sebelumnya.


Generative AI Model Types
Text-to-Text
Model text-to-text dengan mulus mengubah input bahasa alami menjadi output teks yang sesuai. Secara khusus dilatih untuk memahami dan menghasilkan pemetaan antara pasangan teks, model ini menawarkan seperangkat alat serbaguna yang dapat diterapkan dalam berbagai tugas, seperti terjemahan multibahasa, ringkasan dokumen yang ringkas, ekstraksi informasi yang efisien, operasi pencarian yang tepat, pengelompokan konten dinamis, dan bahkan penyuntingan serta penulisan ulang konten yang nuansa.
Text-to-Image
Model teks-ke-gambar mewakili batasan baru dalam AI, yang dilatih dengan dataset luas yang terdiri dari gambar yang dipasangkan dengan deskripsi teks singkat. Dengan memanfaatkan metodologi seperti difusi, dengan secara bertahap memperbaiki pemahaman model tentang hubungan rumit antara petunjuk tekstual dan fitur visual yang sesuai, model-model ini unggul dalam menerjemahkan petunjuk tekstual menjadi keluaran visual yang hidup. Aplikasi utamanya terletak pada bidang pembuatan dan pengeditan gambar, di mana kemampuan model untuk memahami dan mewujudkan konsep visual dari petunjuk tekstual meningkatkan kreativitas dan efisiensi.
Apa Selanjutnya? Siap untuk Aplikasi Praktis?


Untuk menjalankan tugas GenAI ini dengan lancar di edge, NVIDIA Jetson mampu menjalankan model bahasa besar (LLM), transformer visi, dan difusi stabil secara efisien dan stabil secara lokal. Ini termasuk model Llama-2-70B terbesar di Jetson AGX Orin, dan Llama-2-13B dengan tingkat interaktif. Didukung oleh Jetson Orin NX yang kuat dengan kinerja AI hingga 100 TOPS, perangkat edge reServer Industrial J4012 kami memberikan kemampuan untuk melakukan tugas analitik video di lokasi dengan lancar. Sebagai penyimpanan lokal yang dapat diperluas dengan 2 drive bay untuk HDD/SSD SATA 2,5", perangkat ini dipadukan dengan 5 port 5 GbE RJ45, di mana 4 di antaranya untuk 802.3af PSE, menjadikannya pilihan ideal untuk menerapkan model bahasa besar lokal dengan pemrosesan waktu nyata melalui beberapa aliran.
Anda dapat menggunakan miniGPT-4 untuk membuat konten tulisan, menghasilkan deskripsi gambar, menyebarkan agen percakapan virtual, dan bahkan membuat situs web dari draf tulisan tangan.
Dalam menangani persepsi lingkungan, Vision2Audio yang berbasis model LLaVA, menjembatani kesenjangan antara visi dan suara, memungkinkan individu dengan gangguan penglihatan untuk merasakan lingkungan sekitar melalui instruksi verbal.
Untuk memahami input multimodal, Anda dapat menggunakan CLIP untuk menggeneralisasi di berbagai kelas melalui pembelajaran tanpa tembakan. Ini bekerja dengan baik dalam berbagai tugas, mulai dari mengklasifikasikan gambar berdasarkan deskripsi tekstual hingga mengambil gambar dengan kueri tekstual spesifik. Kemampuannya meluas ke deteksi objek, pembuatan gambar berbasis teks, dan berbagai upaya pemrosesan bahasa alami seperti analisis sentimen dan menjawab pertanyaan visual, berkembang sebagai alat yang kuat untuk aplikasi AI yang memerlukan pemahaman mendalam tentang data gambar dan teks. Lihat demo tentang cara menerapkan CLIP pada reComputer Jetson Orin NX.
DigiWare
Robotic & Electronic Components Online Store in Indonesia
Komplek Ruko RMI Blok i No. 22
031-5039460
© 2024. All rights reserved.
customerservice@digiwarestore.com
Surabaya, Jawa Timur, 60284
Our Social Media
Marketplace
Tokopedia ( Surabaya )
Tokopedia ( Bekasi )