

Implementasi Model YOLOv8 pada NVIDIA Jetson menggunakan TensorRT
Seeed Studio AIoT Marketing and Partnership Diterjemahkan oleh : Digiware
1/17/20252 min baca
Ultralytics YOLOv8 adalah model canggih terkini (state-of-the-art/SOTA) yang dibangun berdasarkan kesuksesan versi YOLO sebelumnya dan memperkenalkan fitur-fitur baru serta perbaikan untuk meningkatkan kinerja dan fleksibilitas lebih lanjut. YOLOv8 dirancang dan diakui sebagai model yang cepat, akurat, dan mudah digunakan, menjadikannya pilihan yang sangat baik untuk berbagai tugas deteksi dan pelacakan objek, segmentasi instance, klasifikasi gambar, dan estimasi pose.
Memindahkan model SOTA ke perangkat edge berukuran kecil


Pada tahun 2022 dan tahun ini, telah diperkenalkan cara untuk menerapkan YOLOv5 & YOLOv8 pada perangkat NVIDIA Jetson menggunakan DeepStream-Yolo (kredit untuk proyek ini!). Dengan mengikuti panduan tersebut, performa sekitar 60 fps pada resolusi 640×640 dapat dicapai menggunakan Jetson Xavier NX. Selain itu, uji kinerja telah dilakukan untuk semua tugas visi komputer yang didukung oleh YOLOv8 yang berjalan pada reComputer J4012 dengan modul NVIDIA Jetson Orin NX 16GB.
(Tahukah Anda bahwa seri terbaru reComputer Industrial Orin dengan desain tanpa kipas kini tersedia, dilengkapi lebih banyak antarmuka untuk komunikasi dengan mesin pabrik?)
Kini, model YOLOv8 dapat diterapkan langsung menggunakan TensorRT.
Selain model YOLOv8 Detect, pengujian juga dilakukan pada model Segment dan Pose yang menunjukkan performa inferensi yang mengesankan di perangkat edge NVIDIA Jetson dari Seeed. Panduan wiki ini dirancang untuk membantu pengguna memaksimalkan potensi YOLOv8. Dokumentasi YOLOv8 juga tersedia untuk informasi lebih lanjut, termasuk model YOLOv8 yang sudah dilatih di Roboflow Universe, serta opsi pelatihan dan anotasi cepat melalui Roboflow dan Ultralytics Hub.
YOLOv8 models
Object Detection
Image Segmentation
Image Classification
Pose Estimation
Object Tracking
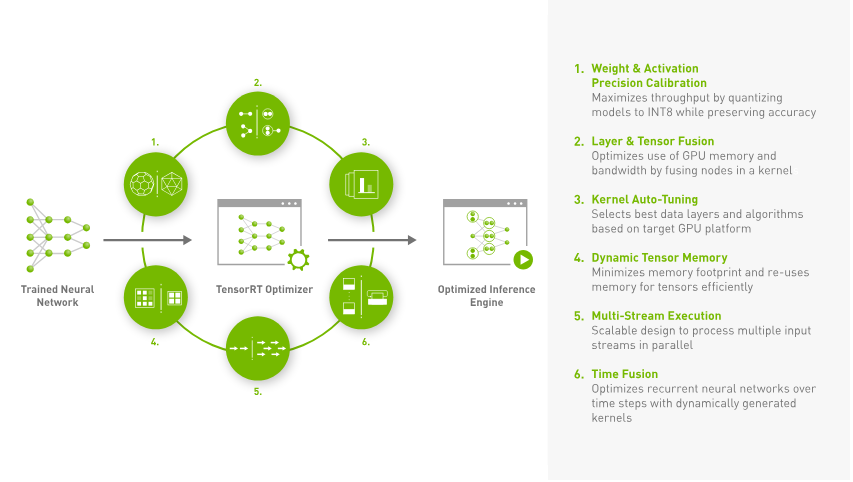
Kenapa TensorRT?
NVIDIA® TensorRT™ adalah SDK untuk inferensi pembelajaran mendalam dengan kinerja tinggi. SDK ini mencakup pengoptimal inferensi pembelajaran mendalam dan runtime yang dirancang untuk memberikan latensi rendah serta throughput tinggi pada aplikasi inferensi. TensorRT adalah pustaka yang dikembangkan oleh NVIDIA untuk mempercepat proses inferensi pada GPU NVIDIA.
Dengan menggunakan TensorRT, kecepatan inferensi dapat meningkat hingga lebih dari 2 hingga 3 kali lipat dibandingkan dengan menjalankan model asli seperti PyTorch dan ONNX tanpa TensorRT. Hal ini membuat TensorRT sangat cocok untuk berbagai layanan real-time dan aplikasi tertanam.
Kenapa TensorRT?
NVIDIA® TensorRT™ adalah SDK untuk inferensi pembelajaran mendalam dengan kinerja tinggi. SDK ini mencakup pengoptimal inferensi pembelajaran mendalam dan runtime yang dirancang untuk memberikan latensi rendah serta throughput tinggi pada aplikasi inferensi. TensorRT adalah pustaka yang dikembangkan oleh NVIDIA untuk mempercepat proses inferensi pada GPU NVIDIA.
Dengan menggunakan TensorRT, kecepatan inferensi dapat meningkat hingga lebih dari 2 hingga 3 kali lipat dibandingkan dengan menjalankan model asli seperti PyTorch dan ONNX tanpa TensorRT. Hal ini membuat TensorRT sangat cocok untuk berbagai layanan real-time dan aplikasi tertanam.
Berikut tiga metode yang direkomendasikan untuk melatih model:
1. Ultralytics HUB
Ultralytics HUB memungkinkan integrasi dengan Roboflow sehingga semua proyek Roboflow Anda dapat langsung tersedia untuk pelatihan. Di sini juga disediakan notebook Google Colab untuk memulai proses pelatihan dengan mudah sekaligus memantau kemajuan pelatihan secara real-time.
2. Menggunakan Workspace Google Colab
Pada metode ini, API Roboflow digunakan untuk mengunduh dataset langsung dari proyek Roboflow.
3. Menggunakan PC Lokal
Metode ini memerlukan PC dengan GPU yang cukup kuat. Anda juga perlu mengunduh dataset secara manual sebelum memulai proses pelatihan.
Cara Melatih Model YOLOv8 Pertama Anda
DigiWare
Robotic & Electronic Components Online Store in Indonesia
Komplek Ruko RMI Blok i No. 22
031-5039460
© 2024. All rights reserved.
customerservice@digiwarestore.com
Surabaya, Jawa Timur, 60284
Our Social Media
Marketplace
Tokopedia ( Surabaya )
Tokopedia ( Bekasi )