

Jetson All-in-One: Pengembangan dan Penerapan Model AI di Edge
Seeed Studio AIoT Marketing and Partnership Diterjemahkan oleh : Digiware
12/4/20245 min baca
Dalam bidang Machine Learning yang berkembang pesat, pelatihan model AI merupakan bagian yang sudah tidak asing lagi, tetapi menantang dan rumit. Secara tradisional, tugas ini dipikul oleh server cloud yang tangguh, yang menggunakan kemampuan komputasinya untuk memperbarui parameter model dengan kumpulan data yang ekstensif. Namun, narasinya berubah, berkat kemajuan luar biasa yang dicapai dalam pengembangan Edge AI dan komputasi terdistribusi.
Dalam blog ini, kita akan melihat lebih dekat bagaimana alur kerja pengembangan dan penerapan AI tradisional direalisasikan, mengeksplorasi manfaat menyelesaikan seluruh alur kerja ini di edge, dan memeriksa panduan langkah demi langkah untuk melangkah maju dalam aplikasi AI Anda.
Siklus Pengembangan Aplikasi AI
Dalam pendekatan konvensional, perjalanan penerapan AI dimulai dengan memperoleh dan mengatur data, sebagai dasar untuk melatih model yang tangguh. Kumpulan data ini diberi label dengan cermat, sehingga menghasilkan kumpulan informasi beragam yang mempercepat pembelajaran model. Setelah persiapan data, pelatihan model dilakukan pada server komputasi yang tangguh, dengan mengulang kumpulan data untuk mengoptimalkan parameter. Model yang telah disetel dengan baik kemudian dioptimalkan untuk eksekusi yang lancar pada perangkat tertentu, yang penting untuk performa puncak. Akhirnya, model disebarkan ke perangkat Jetson melalui cloud, siap untuk aplikasi AI di dunia nyata.
Karena kinerja model AI sangat bergantung pada input data dunia nyata dalam realitas yang terus berubah, seperti persimpangan jalan, tempat parkir, pertokoan, QSR, daur ulang limbah, robotika, dll., masalah akan muncul dengan kekhawatiran tentang latensi, bandwidth, dan privasi. Hal ini dapat menyebabkan kesulitan saat memproses di cloud terpusat atau pusat data perusahaan.
Namun, bagaimana jika kita mempertimbangkan untuk menyelesaikan seluruh proses di tepian?
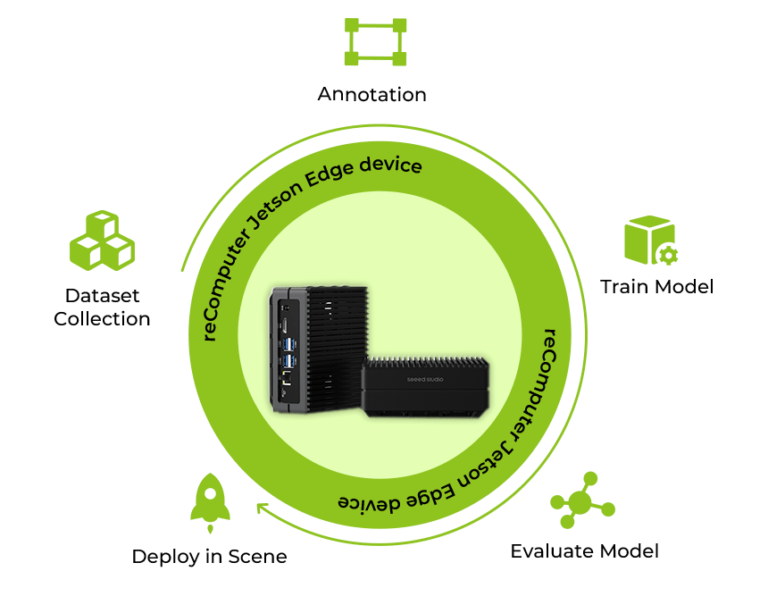
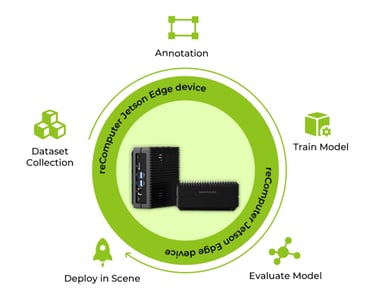
Mengapa Melatih dan Menyebarkan Model di Edge?
1. Pelatihan pada Perangkat:
Perangkat Jetson, yang dilengkapi dengan daya komputasi yang memadai, memungkinkan pengembang untuk melakukan pelatihan di perangkat. Ini berarti bahwa model AI dapat diperbarui dan dilatih ulang secara langsung di perangkat edge berdasarkan input data baru yang berkelanjutan dari lingkungan nyata, tanpa perlu mengirim data kembali ke server pusat atau cloud untuk pelatihan, yang memungkinkan alur kerja yang terdesentralisasi dan efisien.
2. Meningkatkan Privasi
Jetson meningkatkan privasi dengan memproses data secara lokal dan hanya mengunggah wawasan yang dianalisis ke cloud. Bahkan ketika sebagian data dikirimkan untuk pelatihan, anonimisasi yang kuat melindungi identitas pengguna. Hal ini tidak hanya menjaga privasi tetapi juga menyederhanakan kepatuhan terhadap peraturan data.
3. Operasi Lebih Stabil
Alih-alih menangani beban kerja yang berfluktuasi dan potensi kemacetan pada server komputasi tradisional, efisiensi Jetson dapat ditunjukkan melalui kemampuannya menjalankan operasi dengan presisi dan stabilitas, berjalan 7x24 tanpa perawatan manusia yang sering dan perbaikan yang rumit.
4. Minimalkan Latensi
Perangkat Jetson Edge menonjol sebagai perangkat yang sangat ampuh dalam mengurangi latensi karena pendekatan pemrosesan datanya yang efisien. Perangkat ini menghilangkan kebutuhan data untuk berpindah-pindah antara ujung penyebaran dan server pusat, yang merupakan faktor penting untuk mencapai respons waktu nyata dalam aplikasi. Dengan berfokus pada pengiriman data yang ringkas dan terkini, bukan pada kumpulan data besar yang lengkap, Jetson mengoptimalkan efisiensi bandwidth. Perangkat ini hanya memberikan informasi penting yang dibutuhkan untuk pengambilan keputusan yang cepat, menjadikan Jetson sebagai solusi yang tangguh untuk aplikasi yang menuntut komputasi yang cepat dan responsif.
Selesaikan Seluruh Prosedur di Jetson Orin NX
Sekarang, saya senang memandu Anda untuk melatih dan menerapkan model deteksi objek yang mengacu pada algoritma deteksi objek YOLOv8 untuk jalan raya yang padat, di mana kami menggunakan reComputer J4012 Jetson Orin NX 16GB dengan versi Jetpack 5.1.1 yang telah terinstal sebelumnya. Kami menghargai kontribusi teknisi aplikasi kami Youjiang untuk membangun demo ini dan mencari tahu jalur yang jelas, silakan juga periksa detail lengkapnya di wiki ini .
Koleksi Dataset
Kami memiliki dua metode untuk menyiapkan kumpulan data berkualitas tinggi untuk kinerja model yang baik:
1. Unduh kumpulan data publik sumber terbuka yang telah diberi anotasi sebelumnya
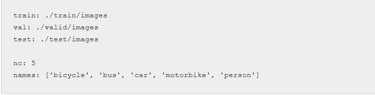
Anda dapat menemukan kumpulan data publik yang tepat dan sesuai untuk skenario aplikasi Anda melalui platform terbuka seperti Roboflow , Kaggle , dan sebagainya. Setelah mengunduh kumpulan data proyek Deteksi lalu lintas dari Kaggle, Anda perlu mengubah jalur yang mengarah ke lokasi set pelatihan, pengujian, dan validasi dalam file data.json.

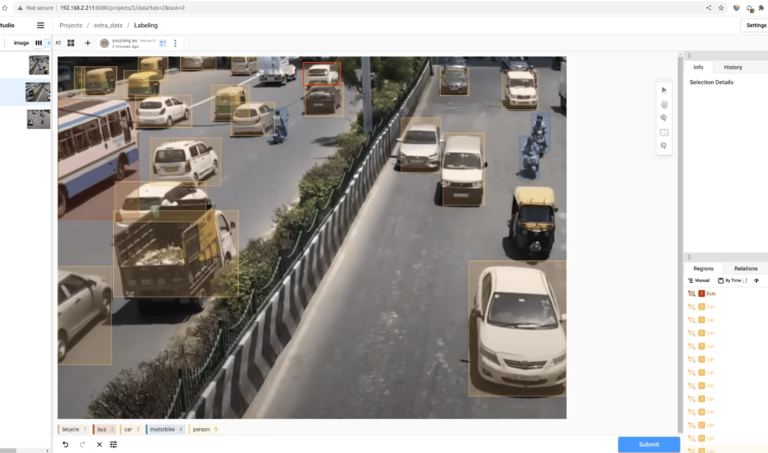
2. Kumpulkan dan beri label gambar sebagai kumpulan data Anda untuk pelatihan
Mulailah membuat anotasi pada gambar dengan mudah menggunakan Label Studio . Sebelum melakukannya, instal dan jalankan alat anotasi sebagai berikut:


Ikuti panduan langkah demi langkah untuk membuat proyek anotasi Anda, dan ekspor kumpulan data dalam format YOLO. Untuk mengaturnya dengan data yang diunduh bersama-sama, Anda dapat menyimpan semua gambar ke folder train/images, lalu menyalin file teks anotasi yang dihasilkan ke folder train/labels, kedua folder tersebut untuk kumpulan data publik.
Siapkan Lingkungan Runtime
Di sini kita akan mengunduh kode sumber YOLOv8 di reComputer, memodifikasi requirements.txt terlebih dahulu, dan menginstal PyTorch versi Jetson. Ikuti perintah wiki .
Ingatlah untuk memeriksa apakah Anda telah berhasil menginstal YOLO:

Latih Model Anda
Revisi skrip Python Anda dengan mengedit sebagai berikut, penggunaan pendekatan CLI untuk melatih model dengan menyiapkan konfigurasi berbeda berdasarkan persyaratan skenario spesifik Anda adalah opsional. Langkah-langkah lengkap untuk bagian pelatihan dapat ditemukan di wiki .

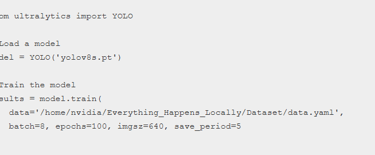
Setelah kemajuan pelatihan selesai, Anda akan melihat file bobot model disimpan di folder tertentu:


Validasi & Penerapan Model
Dengan memverifikasi hasil prediksi, pertama-tama Anda akan mengetahui apakah model dapat menjalankan kapabilitas yang diharapkan dalam skenario nyata. Namun, ini hanya verifikasi kelayakan model, tanpa mempertimbangkan kecepatan inferensi berdasarkan persyaratan praktis dalam aplikasi dunia nyata. Jadi, menemukan keseimbangan antara efisiensi dan akurasi prediksi memainkan peran penting selama proses penerapan. Mesin Inferensi TensorRT dapat membantu meningkatkan kecepatan inferensi model. Ikuti wiki untuk membuat file inference.py dan ganti bagian model dan cap dengan jalur Anda.
Untuk membuat model yang lebih serba guna dengan inferensi yang lebih cepat, model terkuantisasi juga penting untuk diterapkan dalam bagian penerapan. Berdasarkan pengujian dalam demo ini, kinerja inferensi dapat ditingkatkan dari 21,9 FPS menjadi 29,76 FPS setelah menggunakan model terkuantisasi.


Ke depannya, tetap penting untuk fokus pada peningkatan kecepatan inferensi. Dengan memanfaatkan kinerja AI Orin NX yang luar biasa, yang mencapai hingga 100 TOPS, langkah selanjutnya melibatkan penyempurnaan model AI untuk membuka kecepatan yang lebih tinggi dalam inferensi AI edge.
Proses pengembangan AI juga dapat dipercepat dengan menyinergikan AI generatif dengan seluruh siklus, yang tidak hanya dapat meningkatkan kemampuan generatif model dengan perluasan kumpulan data yang cepat, tetapi juga melatih ulang model AI dengan kemampuan pembelajaran transfer berdasarkan sejumlah kecil data khusus tugas. Semua kemajuan ini dapat ditangani dengan perangkat edge reComputer Jetson Orin kami, lalu diintegrasikan lebih lanjut dengan lancar ke dalam pengembangan aplikasi AI edge menyeluruh dan jalur penyebaran, yang terus menunjukkan inovasi di berbagai bidang dan ekosistem industri.
DigiWare
Robotic & Electronic Components Online Store in Indonesia
Komplek Ruko RMI Blok i No. 22
031-5039460
© 2024. All rights reserved.
customerservice@digiwarestore.com
Surabaya, Jawa Timur, 60284
Our Social Media
Marketplace
Tokopedia ( Surabaya )
Tokopedia ( Bekasi )