

Menerapkan Klasifikasi Zero-shot CLIP di Jetson Orin – Temukan dan Kategorikan Data dengan Cepat Tanpa Pelatihan
ARTIFICIAL INTELLIGENCE
Seeed Studio AIoT Marketing and Partnership Diterjemahkan oleh : Digiware
8/13/20255 min baca
Metode tradisional untuk klasifikasi gambar memakan banyak waktu dan sumber daya. Metode ini memerlukan jutaan gambar berlabel sebagai persiapan dataset yang sangat besar dan harus konsisten dengan objek target Anda. Dataset ini kemudian digunakan untuk melatih model klasifikasi yang diawasi pada langkah berikutnya.
Namun, pelatihan yang diawasi tidak selalu memberikan performa yang baik untuk penggunaan umum. Misalkan Anda akan menguji model dengan gambar lain di domain yang berbeda atau menyertakan objek serupa dalam skenario aplikasi yang tidak familiar. Dalam kasus ini, model mungkin mengidentifikasi objek sebagai kelas yang tidak diharapkan. Di sinilah CLIP (Contrastive Language–Image Pretraining) melepaskan kekuatan pembelajaran multimodal dengan cepat.
Memahami CLIP
Jadi, apa itu CLIP?
CLIP, yang merupakan singkatan dari Contrastive Language-Image Pretraining, adalah model visi komputer yang dikembangkan oleh OpenAI. Model ini unggul dalam memahami hubungan antara gambar dan deskripsi tekstual yang sesuai, dibangun berdasarkan sejumlah besar pekerjaan tentang transfer zero-shot, supervisi bahasa alami, dan pembelajaran multimodal.
Arsitektur Dasar
Pembelajaran Kontrastif dalam Pra-pelatihan
CLIP menggunakan arsitektur Vision Transformer (ViT) untuk memproses gambar, memungkinkan model menangkap hubungan global di antara fitur-fitur gambar. Sementara itu, untuk pemrosesan teks, CLIP menggunakan arsitektur berbasis transformer, yang melakukan tokenisasi dan memproses teks melalui lapisan transformer untuk memahami hubungan semantik dalam deskripsi tekstual tanpa memprediksi teks kata demi kata.
Model ini dilatih menggunakan pasangan gambar dan teks. Tujuannya adalah untuk meminimalkan jarak antara pasangan positif (yang terdiri dari gambar dan deskripsi yang sesuai) dan memaksimalkan jarak antara pasangan negatif (yang terdiri dari gambar dan deskripsi yang dipilih secara acak). Tujuan pembelajaran kontrastif ini mendorong model untuk mempelajari representasi yang bermakna di mana konten yang berhubungan berdekatan dan konten yang tidak berhubungan terpisah.
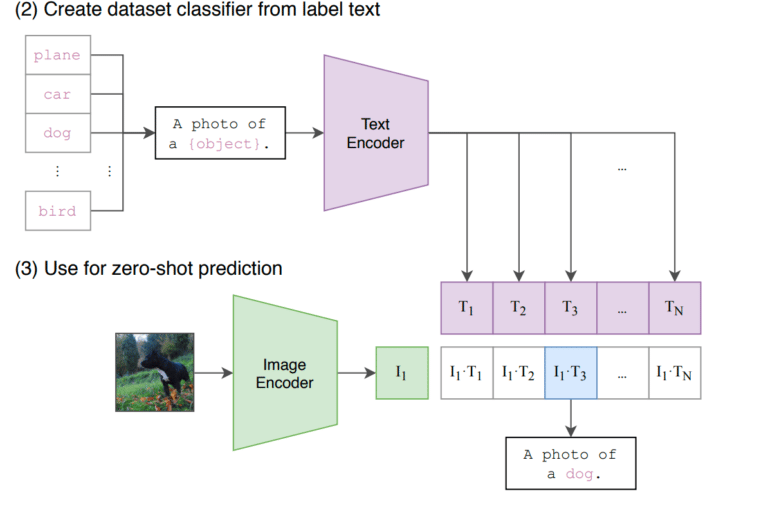
Image from Paper “Learning Transferable Visual Models From Natural Language Supervision“
Penyempurnaan (Fine-tune) untuk Tugas-tugas Hilir
Setelah pra-pelatihan, CLIP dapat disempurnakan (fine-tuned) pada tugas-tugas hilir tertentu dengan dataset khusus tugas. Anda dapat dengan mudah menyesuaikan perilaku CLIP untuk tugas dan domain tertentu dengan prompt engineering. Dengan memanfaatkan templat prompt atau bahkan prompt ensembling, yang menggunakan beberapa templat prompt dengan modifikasi kontekstual yang lebih banyak ditambahkan agar sesuai dengan kemungkinan situasi, akurasi pencocokan kesamaan dapat ditingkatkan.
Mengapa CLIP Penting sebagai Model Dasar?
Tidak seperti model tradisional yang membutuhkan dataset berlabel ekstensif untuk pelatihan, CLIP memanfaatkan pendekatan unik—pra-pelatihan pada dataset besar yang berisi pasangan gambar-teks dari Internet. Hal ini memungkinkannya untuk melakukan berbagai macam tugas tanpa memerlukan data pelatihan khusus tugas. Kemampuan model untuk menghubungkan visi dan bahasa membuatnya mahir dalam tugas-tugas seperti klasifikasi gambar dan bahkan menghasilkan deskripsi tekstual untuk gambar.
Anda hanya perlu menentukan prompt atau deskripsi yang mungkin dimiliki objek di suatu adegan, lalu CLIP akan membantu Anda memprediksi kelas yang paling mungkin untuk gambar atau video yang diberikan berdasarkan pengetahuannya yang luas.
Dalam panduan ini, kami akan menunjukkan wawasan aplikasi dan performa penggunaan CLIP di Edge. Pada dasarnya, CLIP dapat diterapkan untuk:
Mesin pencari iklan: mengklasifikasikan kategori iklan video, yang ditandai dengan skenario pengambilan gambar atau objek utama tertentu.
Moderasi konten: mengidentifikasi dan menandai konten yang berpotensi tidak pantas atau berbahaya dalam gambar dan video.
Rekomendasi video SNS: mengklasifikasikan konten video dan memberikan rekomendasi berdasarkan minat atau riwayat tontonan audiens.
Menentukan periode penting dari suatu peristiwa dalam video yang panjang: meningkatkan efisiensi bagi polisi untuk menemukan bukti kejahatan tepat waktu.
Otomatisasi proses di QSR (Quick Service Restaurant): memeriksa bahan dan saus apa yang harus diletakkan di pizza yang diantar, dan memberikan daftar produksi sesuai dengan perbandingan visual.
Referensi desain interior rumah: membantu Anda menemukan ide desain interior yang mirip secara visual berdasarkan gambar gaya dekorasi pilihan yang Anda berikan.
Kita akan melihat bahwa arah industri dan aplikasi CLIP tidak terbatas! Jadi sekarang, mari kita selami lebih dalam tentang cara menerapkan CLIP di edge untuk menyelesaikan klasifikasi gambar dan tugas proyek lainnya.
Mengapa CLIP Penting sebagai Model Dasar?
Berikut adalah beberapa demo menarik yang telah kami terapkan model CLIP pada reComputer J4012 berbasis NVIDIA Jetson Orin NX 16GB menggunakan Roboflow Inference Server. Anda dapat mengambil referensi dari blog Roboflow untuk panduan langkah demi langkah. Namun, Anda hanya perlu mengubah bagian instalasi server Inference pertama menjadi kode berikut karena kami menggunakan GPU dan menambahkan dukungan TensorRT:

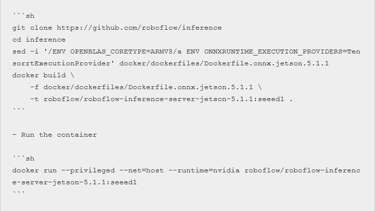
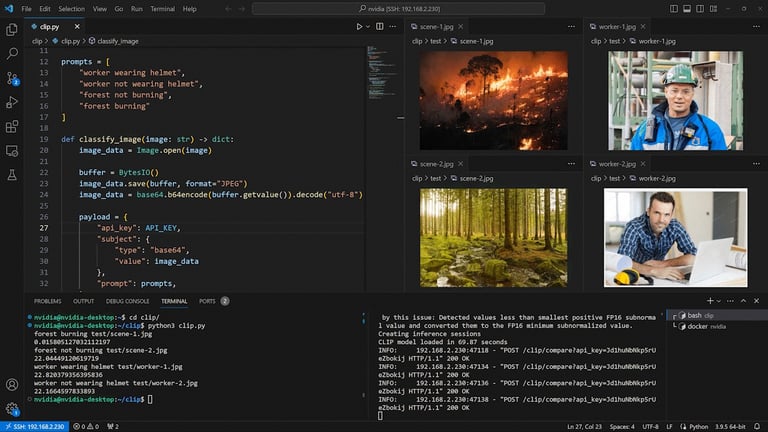
Pasangan Gambar-Prompt
Sekarang Anda dapat dengan mudah mengklasifikasikan gambar ke dalam berbagai kategori tanpa melatih model Anda terlebih dahulu.
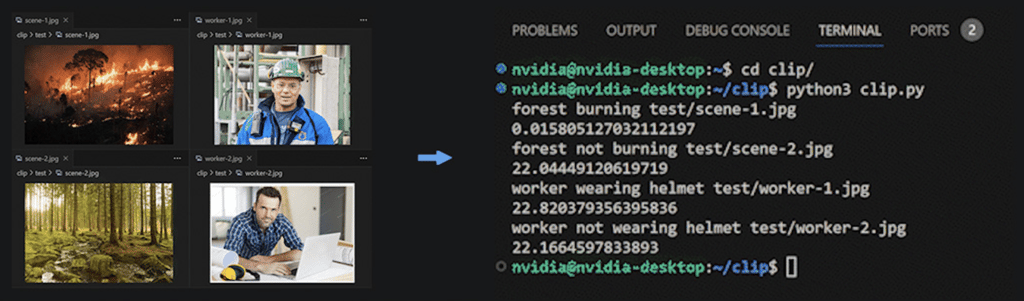
Anda hanya perlu memulai container Docker Roboflow Inference Server di perangkat Jetson Edge, menentukan kunci Roboflow API, dan menjalankan skrip demo untuk mulai mengklasifikasikan berbagai gambar berdasarkan prompt yang Anda tentukan. Kami telah menggunakan Jetson Orin NX 16GB untuk demo ini dan berhasil mencapai performa sekitar 22 FPS dengan presisi TensorRT FP16!
Yang perlu Anda pertimbangkan adalah prompt engineering—yaitu, menemukan prompt yang lebih akurat atau tepat untuk mendeskripsikan adegan gambar dengan jelas demi performa klasifikasi yang lebih baik. Ini berarti Anda harus memberi tahu CLIP apa yang harus dikenali dalam gambar tersebut. Seluruh proses untuk menemukan prompt yang benar ini bisa menjadi uji coba yang panjang dan memerlukan beberapa kali percobaan.
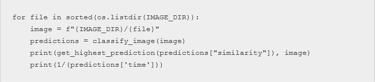
Jika Anda juga ingin menunjukkan kecepatan inferensi seperti yang dilakukan demo kami, Anda dapat dengan mudah menambahkan bagian ini di bagian output hasil cetak:

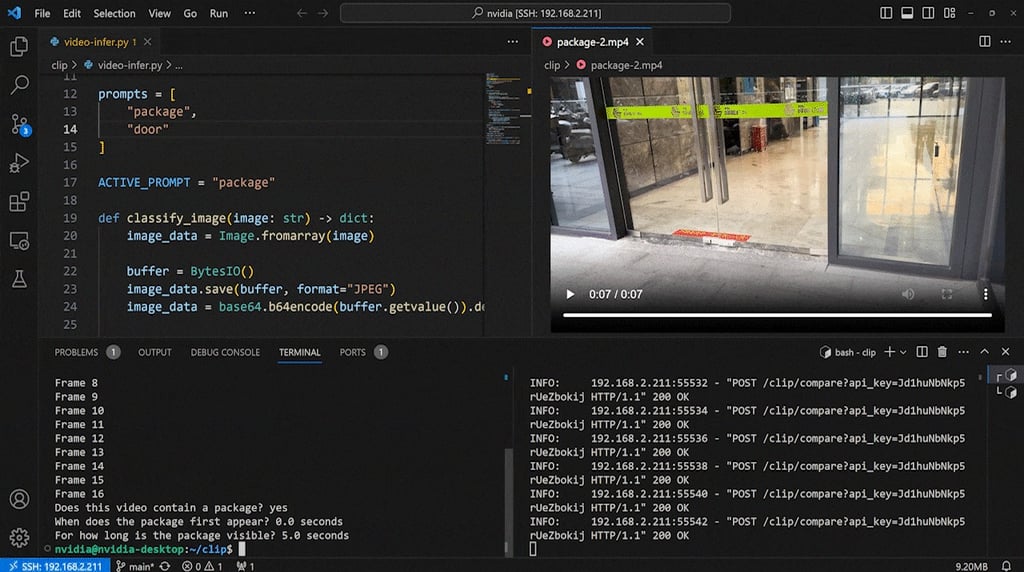
Klasifikasi Tema Video
Memahami skenario video melibatkan beberapa langkah:
Memecah video menjadi bingkai (frame) individual.
Menerapkan CLIP secara independen pada setiap bingkai untuk pemahaman gambar.
Mengintegrasikan informasi temporal di seluruh bingkai.
Dengan memadukan fitur-fitur yang diekstraksi dari bingkai individual dan konteks temporalnya, model menciptakan representasi yang menangkap konten dan konteks keseluruhan dari video. Fitur-fitur yang dipadukan ini kemudian digunakan untuk klasifikasi skenario, memprediksi aktivitas atau skenario yang digambarkan.
Penyempurnaan (fine-tuning) dataset yang berisi bingkai video dan label skenario mungkin diperlukan untuk mengadaptasi CLIP ke persyaratan spesifik dari tugas video. Performa model dievaluasi menggunakan metrik standar, dan penyesuaian dilakukan sesuai kebutuhan untuk hasil yang optimal.
Dalam demo ini, kami menggunakan CLIP untuk mengidentifikasi video sebagai adegan yang berisi sebuah paket. Kami dapat mengklasifikasikan jenis skenarionya, pada stempel waktu (timestamp) berapa paket pertama kali muncul, dan berapa lama paket itu terlihat di adegan. Ini bisa menjadi eksperimen yang sempurna untuk mencegah pencurian paket kiriman. Cukup ikuti blog Roboflow untuk mengklasifikasikan video langkah demi langkah, dan jangan lupa untuk mengimpor pustaka supervision di awal karena kita akan menggunakannya untuk memecah video kita menjadi bingkai-bingkai.

DigiWare
Robotic & Electronic Components Online Store in Indonesia
Komplek Ruko RMI Blok i No. 22
031-5039460
© 2024. All rights reserved.
customerservice@digiwarestore.com
Surabaya, Jawa Timur, 60284
Our Social Media
Marketplace
Tokopedia ( Surabaya )
Tokopedia ( Bekasi )