

NVIDIA Jetson with Autodistill: Terapkan Visi Komputer dengan Metode Pelabelan Otomatis yang Efisien
Seeed Studio AIoT Marketing and Partnership Diterjemahkan oleh : Digiware
8/19/20253 min baca
Sebelum kita bisa menggunakan kekuatan perangkat AI Edge Jetson untuk melakukan inferensi dan pemrosesan, selalu ada masalah utama yang memakan waktu dan sumber daya, yaitu persiapan pelabelan dataset. Secara tradisional, melabeli data gambar secara manual memang akurat untuk melatih model, tetapi prosesnya sangat memakan waktu. Autodistill yang digabungkan dengan Grounded-SAM dan YOLOv8 bisa membantu menyederhanakan proses ini dengan melabeli data latihan secara otomatis, terutama untuk skenario pengembangan pada perangkat Edge.
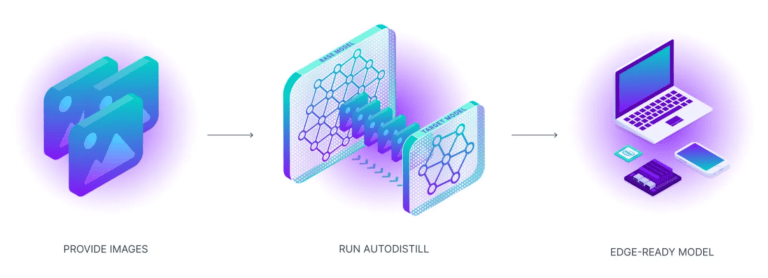
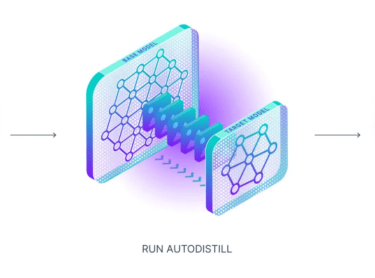
Dengan panduan Colab Roboflow, sangat mudah untuk memulai proses anotasi dan membangun model PyTorch Anda sendiri yang siap untuk diterapkan pada perangkat Edge.
Persiapan Dataset
Setelah memeriksa lingkungan GPU dan menyelesaikan semua instalasi paket yang diperlukan, kita dapat membuat direktori untuk gambar dan video untuk menyimpan sumber data dan gambar yang sudah diberi anotasi sebelumnya.
Dalam aplikasi nyata, kita biasanya ingin menganalisis titik-titik penting dari video streaming daripada harus berhadapan dengan sejumlah besar gambar yang menunggu untuk dijadikan dataset. Untuk bagian anotasi ini, saya telah menyiapkan 10 video yang siap digunakan. Hal pertama yang perlu kita lakukan adalah mengubah video-video ini menjadi gambar dengan menyimpan setiap frame ke-10 dari setiap video. Kemudian, tiga video pertama saya gunakan untuk bagian pengujian untuk mengevaluasi model, dan tujuh video lainnya digunakan untuk bagian pelatihan.


Auttolabel Image
Ketika masuk ke bagian pendefinisian ontologi (struktur label) untuk pelabelan gambar secara otomatis, hal yang perlu diperhatikan adalah bagaimana Model Dasar (Base Model) diberi prompt (perintah teks), bagaimana prompt tersebut tercermin pada dataset Anda, dan objek apa yang akan dideteksi oleh model target Anda. Saya berasumsi bahwa nama prompt untuk setiap objek di pustaka data asli Roboflow seharusnya menggunakan kata-kata yang umum. Jadi, saya menggunakan kata "car" dan ternyata berhasil.


Namun, jika Anda bingung dalam memilih prompt yang tepat, misalnya Anda memiliki beberapa opsi seperti "trash", "rubbish", dan "waste", dan tidak tahu mana yang paling baik untuk melabeli data Anda, Anda bisa mencoba membaca blog "How to Evaluate Autodistill Prompts with CVevals".
Di sana, Anda akan belajar cara membandingkan performa berbagai prompt yang serupa pada dataset, lalu memilih yang terbaik untuk digunakan. Setelah proses dijalankan, Anda akan mendapatkan contoh output berupa gambar-gambar sampel yang sudah diberi label.


Auttolabel Image
Autodistill menawarkan manfaat signifikan untuk aplikasi computer vision Anda:
Efisiensi Biaya dan Kecepatan Lebih Cepat: Menghemat waktu dan sumber daya.
Konsistensi: Mengurangi potensi kesalahan atau inkonsistensi manusia yang bisa terjadi saat pelabelan manual.
Pengurangan Bias Manusia: Meminimalisasi bias yang mungkin muncul dari pelabelan manual.
Namun, penting untuk diketahui bahwa pelabelan otomatis juga memiliki beberapa keterbatasan dan hal yang perlu dipertimbangkan:
Akurasi: Mungkin tidak seakurat pelabelan manual, terutama pada kasus di mana fitur visual yang kompleks atau halus perlu diberi anotasi. Menggabungkan tinjauan manusia dan penyempurnaan label bisa menjadi pilihan yang jauh lebih efisien.
Ketergantungan Model: Metode ini sangat bergantung pada model yang sudah dilatih sebelumnya (pre-trained models), sehingga efektivitasnya tergantung pada kualitas dan relevansi model-model tersebut.

DigiWare
Robotic & Electronic Components Online Store in Indonesia
Komplek Ruko RMI Blok i No. 22
031-5039460
© 2024. All rights reserved.
customerservice@digiwarestore.com
Surabaya, Jawa Timur, 60284
Our Social Media
Marketplace
Tokopedia ( Surabaya )
Tokopedia ( Bekasi )